Original article by ZeldaTPLink, posted in May 2020.
This article is divided in 3 parts. Part 1 analyses only contests that have 128 entrants, 1v1 battles and no extra rounds. Part 2 analyses the other 1v1 contests. FInally, Part 3 lists relevant additions made by B8 users in the original topic.
PART 1
In the past few weeks, both in this board and Discord, I've noticed a discussion about whether the current points scheme of the contests is fair. I refer to the system that awards points for each round in geometrical progression, which is the following way:
Round 1 - 1
Round 2 - 2
Round 3 - 4
Round 4 - 8
Round 5 - 16
Round 6 - 32
Round 7 - 64
The argument I've often seen against this system is that it places too much weight on later matches, in the sense that someone who did very well in early rounds would lose to someone who did not but who got a single great upset in the later rounds. We have seen that in this contest with the Skyrim vs Witcher match, whose 32 point prize made entire early rounds pointless.
This system does follow a mathematical logic, which is that, assuming each game has an equal chance of winning any match, the probability of a given game winning a match goes down by half each round. Therefore, it makes sense for that match to be worth double points. But this logic skips over the fact that not all matches are made equal: while Rocket League vs DBZ was a very debated match, Dark Souls beating Hotline Miami and then beating the winner of that debated match was all but a foregone conclusion. Even the most casual bracket makers would overwhelmingly agree on that. Yet, the Rocket League vs DBZ match is only worth 1 point, while the winner vs Dark Souls is worth 2.
Arguments in favor of this system include its simplicty, and the fact it's based on systems used in bracket contests of real life sports tournaments. Whoever, a sports tournament can have much more variance than a bracket contest, since it depends on human parformance in the moment, while the tastes of a gaming community are much easier to predict based on sales, reviews, overall word of mouth, and previous contests. Hotline Miami will never beat Dark Souls, except with a rally, and rallies big enough to flip such a match around are extremely rare.
Based on this argument, I had an idea to calculate what would be a fairer scoring scheme. Turns out we actually have data on the difficulty of predicting matches for each round, and it's the prediction percentages available in the Contests Stats page! Using that data, I've made a formula to calculate the ideal points for each round. I'm setting Round 1 with 1 point as the standard, then calculating the score for later rounds by dividing the average prediction % of Round 1 by the average prediction % of each round.
DISCLAIMER: the goal of this topic is not to question the merits of any contest winners or winners of any side contest, of this year or any other year. Everyone who have won contests here made a great bracket. The goal is to propose an improvement the scoring system so that future contests award points based on a more accurate measuring of the relative difficulty of each match.
So let's get to the numbers already. Based on the formula I just explained, here is what the points for the recent Game of the Decade should look like:
(note: decimals appear with commas instead of points because that's the Brazilian standard and it's what my Excel is set to. Just pretend you are seeing points instead)
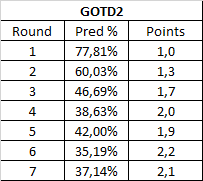
That's very different from a geometrical progression, huh?
Looking closely, Rounds 1 to 4 seem to follow something similar to an arithmetical progression, with each round adding 0.3 points. Round 5 onwards is when it gets wonky, though. I suspect one reason is the BotW effect: as BotW starts making for a larger fraction of the round, the round itself becomes easier to predict. Another thing is that in this year, Round 4 was where most debated matches happened, while Round 5 and beyond were fairly chalky, with the exception of the Skyrim matches.
Still, that doesn't give us an accurate representation of what the diffficulty for each round should be, so I decided to dig deeper. I made the same analysis for a few other contests. For the sake of simplicity, I restricted myself to contests that have 128 entries, 1v1 matches, and 7 rounds. That means GotD1, Character Battle 2010 and Best Game Ever 2015. Here are the results.
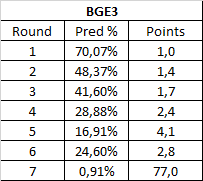
BGE3 is also pretty wonky in the later rounds. That said, the first 4 rounds do show a good degree of consistency.
That 77 in the finals has an obvious reason: Undertale. While this means we can't really take that score as our standard, it does offer a good perspective. 77 is not much above 64, so this shows what it takes for a finals match to actually be worth the 64 points we normally award them: a turbofodder indie game almost nobody heard of getting a Tumblr-fueled rally and winning 7 upsets in a row until it beats Ocarina of Time and wins the contest. Not something that is too likely to happen again, imo. And even then, previous rounds are way below their normal awarded points in difficulty, thanks to being populated by obviously strong games instead of fodder.
Round 5 is worth more than Round 6, and the reason for that is that R6 consisted of Undertale and Ocarina of Time, while R5 was Undertale, Ocarina, Meelee and Super Mario RPG, so on average, R5 has more crazy upsets, including two mega rallies.
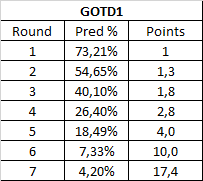
The first game of the decade gives us the more smooth results. Rounds 6 and 7 feel like they spiked a bit more than the usual, but hey, those are the last two rounds so maybe they should do that! And it's still a lot less than 32 and 64. This can also be explained by the fact this contest is famously one of the least predictable ones we've had, with legendary results such as Brawl beating Melee and then losing to Majora's Mask. Also rounds 1 to 3 seem pretty similar to the two previous charts, while 4 and 5 go a big higher.
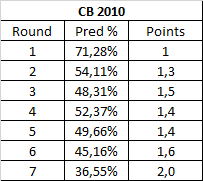
I didn't think I would see a contest chalkier than GotD2, but here we are. The finals are only twice as hard to predict as the average Round 1 match, which makes sense because, well, it's Link > Cloud. Although there are crazy results here and there (i. e. Charizard), they get dampened by the majority of the bracket being a standard Noble Nine, 1v1, no items, final destination story. This is also the easiest Round 4 of the pack, being even easier than Round 3 somehow.
This makes some sense if you think this is the 8th character battle during a time spam of 9 years. There was a ton of data to make predictions from, such as a quick read on the board or the wiki could give someone an idea of what is likely to win here.
(on an unrelated note, this does give us a good idea of what will happen if the next Character Battle doesn't make any big innovation in terms of what characters are in, such as an All Fictional bracket. Expect that contest to even more predictable and have fewer upsets than this year's Game of the Decade).
Conclusions:
One one hand, this research failed to provide a realiable measure of what scoring system will most accurately reflect the difficulty of each round, due to not having a ton of contests to pick from (I could look at other contests, but then I'd have to make arbitrary adjustments for the different bracket sizes). On the other hand, I believe it gave us a great sense of scale: we can see that even in particularly unpredictable contests, the current system still gives way too much weight to late rounds compared to their actual prediction difficulty. A finals match, in order to be actually worth 64 points, should have a prediction rate of 1.56% (assuming Round 1 had 100%, otherwise it should be lower), the semifinals should have 3.13% on average, and so on. And what we usually see instead for later rounds are prediction %s in the double digits. And this is all taking in consideration the fact I'm using data for the overall brackets submitted, not just gurus or B8.
If I had to take a guess at an actual system, my instinct is to take GotD1 as the standard, since it's the one that looks the most neat. I'll then multiply all the numbers by 10 and do some rounding, to get more manageable numbers:
Round 1 - 10
Round 2 - 13
Round 3 - 18
Round 4 - 28
Round 5 - 40
Round 6 - 100
Round 7 - 180
If you think the last two rounds are two high compared to the first one, then you should assume it's because Majora and Brawl getting to the finals is a crazier result than average. In that case, you could settle for something chalkier, and reduce those numbers a bit. I made that adjustment, and also did a little more rounding for early matches.
Round 1 - 10
Round 2 - 15
Round 3 - 20
Round 4 - 30
Round 5 - 45
Round 6 - 75
Round 7 - 120
PART 2
Ok I've decided to do this for the rest of the contests.
We are going to do it from the most recent to the oldest. First, CBX:
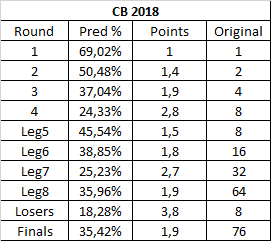
Hmm that is a lot to unpack.
The first four rounds have very similar scorings to GotD1, which suggests my hunch of taking it as the standard was a good one.
The later rounds, though, can't really compare to anything else though, due to Legends/Losers structure. Looking at it, we can see "Round 5" showed a drop in difficulty, due to the possibility of just betting on noble niners to win everything (which worked except for Pikachu and Zeld matches). The next two rounds show a fibonacci-like increase of difficulty (yes, I second on the Fibonacci idea being great). The last legends bracket seems another drop, thanks to Link.
Losers matches are worth 8, but we can see they maybe should have been worth 4. The final Link match is only twice as hard as Round 1 ones, which seems to be a global trend. In a given contest, about 30-40% of casual bracket makers will correctly identify the Zelda entry that is guaranteed to win.
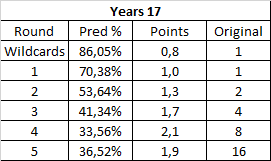
Best Year in Gaming only has one format weirdness, the Wildcards round. I decided to keep Round 1 as the normal instead, so we can see Wildcards is worth about 80% of it (due to having obvious blowouts between old years).
The rest is actually pretty smooth. Years is one of the chalkier brackets, but aside from, again, the finals, it shows a soft progression (1.3, 1.4, 1.4). Not much that I can compare with other contests: not only it's a 5-round contest so round 1 should be intrinsecally more valuable than usual, but it's also fucking Years. Moving on.
So it seems Character Battle 2013 doesn't have prediction % data in the site. This sucks, because I wanted to see how much the Draven picks were worth. Someone feel free to provide them to me if they have it.
Let's go to Rivals, then.
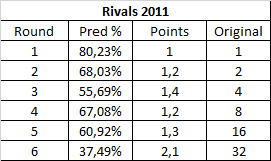
Eh this one is all over the place. I wasn't around at the time of Rivals though, so I don't really know how to explain it. It seems every round after the first one is worth roughly 1.3, until we get to the Link finals which again, is worth about 2. I think this is another very chalky contest though, so it makes sense for numbers to be lower, and the wonkiness could just be the normal statistical deviation.
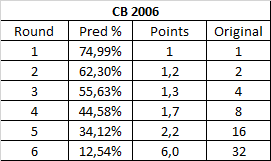
Oh hey I remember this contest! It was the first one I submitted a bracket for. Good times.
The first 5 rounds are rather chalky, which I suspect is the effect of the female bracket. The finals show a number much higher thn the average though (6). Still not even close to the 32 it actually awarded, though. This is probably due to the sheer difficulty in picking Samus over Snake or maybe Crono, I don't think she was the favorite here.
The champions bracket does not have its prediction %s listed, even though I think it also awarded points? At least I know it did for the Guru, based on that other analysys I made a few months ago.
Moving on.
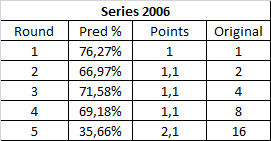
Holy shit what a chalky contest! Every round except for the last one is about as hard at the first, and only the last one is really worth something due to Zelda's upset against Final Fantasy (and it's not that huge of an upset anyway, it's Zelda). Eh... are you people sure you want another Series contest?
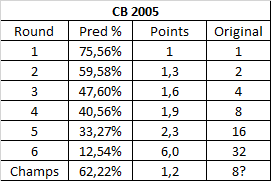
The first 5 matches show a pretty smooth progression, albeit this bracket is a little more chalky than the usual. The finals jump to 6 points though (same scoring as the finals of the 2006 contest). I guess not many people expected Mario to win here? If so, who was the favorite?
The Champions bracket goes back to having a very low scoring, which makes sense because it's when Clinkeroth came back. I don't know how many points these matches were worth though, but since the ones from 2006 were worth 8 points (according to the Guru site), I put that number there. Not that this matters, since they should have been worth 2 points at most, it seems!
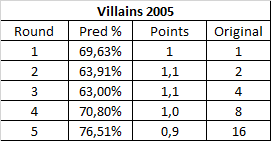
Got villains? I got villains, and the most predictable bracket ever.
Okay, this kind of ties with Series, another mega predictable bracket, but at least that one had a debatable finals. Here, Sephiroth's win is so obvious it's the only round so far that manages to be even easier than the first one (excluding the Years wildcards). Everything else is pretty obvious, too. You could award the same scoring for every round and it would be fair.
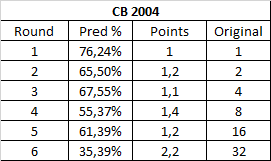
This one is kind of all over the place, except for the finals. I guess at this point of history, Link's domination was still not set in stone.
So rounds 1 to 4 follow the usual progression.
Then in the semi-finals, it just stalls. I figure this is because once you sort out trickier match-ups like FF7 beating Ocarina and CT beating LttP, all that is left is to take square to the win, so this round won't be any harder.
The finals see the usual predictionpercent in the 30-40%, similar to most finals that were won by Zelda games. Only here, it happened during Cloud's era. It's still easier to predict this match than the previous two rounds are on average, which suggests the 32 points warded here were way too many.
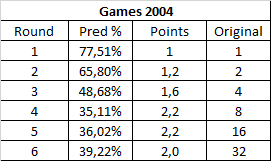
If prediction FF7's dominance in Games 2004 was easy, here it wasn't really. The finals were 10 times harder to predict than the round 1 matches. Still less than 1/3 of what was awarded, though. The semi-finals aren't exactly a cakewalk, either.
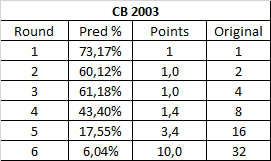
The first 4 rounds are a chalkfest though, with round 4 only being 1.4x harder than round 1, and the first 3 rounds having the same difficulty. This means a character from the final 8 who goes past a difficult match in rounds 1-3 is not likely to have another difficult match in those first three rounds.
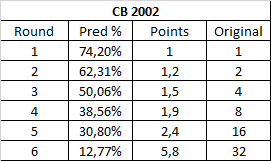
Finally, the original character battle. Rounds 1-4 show another progression similar to other contests, if a little bit chalkier. Round 5 doesn't deviate much. The finals is the big surprise though, with only 12.77% of the brackets predicting Link's win. It would be interesting to see a world where GameFAQs wasn't aware of Link's dominance yet.
PART 3
LordoftheMorons posted:
The idea I threw out for this a few years ago (which I still like) is Fibonacci scoring (e.g. matches in round 1, 2, 3, 4, 5, 6, ... would be worth 1, 2, 3, 5, 8, 13, etc points). This is still exponential (the ratio between point values of matches in successive rounds very quickly converges to ~1.61), but goes up slower than powers of 2 and you still get integer point values.
ShatteredElysium posted:
The contest has 127 matches
Calling the correct 2 finalists and getting the winner correct is worth 200 points (13 matches / 10.23% of the contest)
Calling the first 3 rounds perfectly is worth 192 points (112 matches / 88.18% of the contest)
It is pretty obvious that whilst later rounds should be worth more, they should not be worth that much more. Calling 112 matches in a row correct is significantly more difficult that calling the correct 2 finalists and winner. We have the prediction percentages so someone could run the numbers if they wanted but even when we have an unexpected finalist, I'm sure the chances of getting 2 finalists and the winner right are way higher than the chances of getting the first 112 matches correct.
Ringworm posted:
I would be interested to see how a scoring system purely based on the prediction percentages would work. Have a pool of say 10,000 points per match available, this pool get divided by the amount of people picking the match correctly and that's how much the match is worth.
As an example, lets say there are 10,000 entries and 10,000 points available per match (to keep the maths simple). Match 1, 8,000 people predict correctly. This match would be worth (10,0000 / 8,000) or 1.25 pts. Match 2 is an upset which only 2,000 predict. This would be worth 5 pts (10,000 / 2,000).
You could still have later rounds worth more points by increasing the total points per match (say 10K for Rd 1, 20K Rd 2, 30K Rd 3 etc).
I know this will never happen. I would be interested to know if someone who had traditionally won would have been beaten by someone who tipped more upsets correctly though. As an example, would anyone have beaten Azuarc, who went near perfect from Rd 3 onwards this contest, by picking up enough points in the earlier rounds in the matches he missed (and also correctly predicting enough later round matches)? I would say it's possible, but I wouldn't expect many people would have managed it in this last contest. Probably much more likely in contests with an upset winner, such as L-block, Draven or Undertale.
ShatteredElysium posted:
Some permutations
1 > 2 > 3 > 5 > 8 > 13 > 21
Perfect score = 295 points
Correct final 2 and winner = 85 points / 28.8% of possible points
Correct winner only = 53 points / 18% of possible points
1 > 2 > 3 > 4 > 5 > 6 > 7
Perfect score = 247 points
Correct final 2 and winner = 49 points / 19.8% of possible points
Correct winner only = 28 points / 11.3% of possible points
1 > 2 > 4 > 6 > 8 > 10 > 12
Perfect score = 304 points
Correct final 2 and winner = 74 points / 24.3% of possible points
Correct winner only = 43 points / 14.1% of possible points
1 > 2 > 4 > 8 > 8 > 8 > 8
Perfect score = 312 points
Correct final 2 and winner = 70 points / 22.4% of possible points
Correct winner only = 39 points / 12.5% of possible points
1 > 2 > 4 > 8 > 16 > 32 > 64
Perfect score = 448
Correct final 2 and winner = 200 points / 44.6% of possible points
Correct winner only = 127 points / 28.3% of possible points
How much of the max possible points do you want calling the winner to be worth?
Joelypoely posted:
That Fibonacci sequence idea with the semi-final and final reduced a little bit looks good.
E.g. 1 - 2 - 3 - 5 - 8 - 12 - 15
Keltiq posted:
I calculated scores for some of the brackets from this contest's guru, using the adjusted point scheme from the second post. I took the top 15, the five highest Skyrim brackets, the cookie, and a couple I remembered having strong early rounds.
2 JONAELEON1 - 2010 (428)
1 azuarc - 1985 (429)
6 Ngamer64 - 1945 (412)
3 fpce666 - 1930 (421)
4 Furious Fura - 1930 (417)
12 Glenn_And_Toad - 1930 (410)
7 Hbthebattle - 1925 (412)
5 Seanchan - 1915 (414)
9 foxhead84 - 1915 (411)
10 DpObliVion - 1915 (411)
11 MetalmindStats - 1915 (410)
26 Advokaiser - 1915 (394)
14 Keltiq - 1900 (407)
22 yoblazer - 1900 (397)
13 XIII_Rocks - 1895 (408)
28 TAFKAHurricane - 1895 (390)
8 Lightning Strikes - 1890 (411)
15 davidponte - 1885 (400)
29 Camden - 1885 (390)
27 DoctorJimmy133 - 1885 (391)
32 The Guru Cookie - 1880 (388
51 bossman_coolguy - 1830 (379)
55 Paratroopa1 - 1815 (380)
Most notable to me is that the brackets I selected for their good early rounds were still much lower than the rest - bossman had the best round 1 (and witcher) but a very messy middle contest, while Para is held back almost entirely by his bad round 3 (and not having witcher). Also Advokaiser going up like 14 places - in the original scoring system, he lost more points from Skyrim than he did in the entire rest of his bracket (32 out of 54), whereas in this system it was only about a third of his lost points (75 out of 215).
SecretSquirrel posted:
I'd actually be somewhat interested in seeing the meta-game of the contests change with something like this.
For example, we know that prediction percentages tend to be higher for mainstream hits like GTA, Red Dead, Overwatch, previous rally benefactors, etc. Meanwhile, things like non-FF RPGs tend to be undervalued by the casual bracketmaker. So, does this incentivize Board 8ers to seek out potential upsets based on potentially lucrative payoffs? Most of us knew better that Cuphead wasn't likely to take down GTA V pre-contest, but imagine the traction the "Cupset" would have had knowing you could get a possible 15% prediction bonus as early as Round 2? To say nothing of the 15% bonus that you would have got when P4G got when it did take down GTA, which was still a Guru upset in our timeline, but probably not a Guru upset in this timeline.
azuarc posted:
First I'm seeing this topic, and I'm glad someone's talking about it. I do honestly believe Jona was more deserving of winning than I was. His TLOU whiff opened the door just barely wide enough for one person to slip through, and I think he honestly should have held on for the win. IIRC, and I had an entire post written about this in the guru topic before I deleted it, the breakdown went something like this:
I missed:
5 R1 (5 pts)
5 R2 (10 pts)
1 R3 (4 pts)
0 R4 onward
----------------
-19 overall
Jona missed:
4 R1 (4 pts)
2 R2 (4 pts)
1 R3 (4 pts)
1 R4 (8 pts)
----------------
-20 overall
So basically I missed 11 matches and he missed 8. 7 of those were effectively the same, but instead of missing Rayman>Celeste, FFXV>Hollow Knight, HZD>Borderlands 2, and Shovel Knight>not-Undertale, he missed a single R4 match in Dark Souls>The Last of Us.
Should missing one R4 match be worth more than three in R2 and one in R1? Probably not. It's only two rounds deeper into the contest. Had he missed Witcher>Skyrim, yes, that's an important enough match to merit being worth more than 7 points, but I think the penalty here was a bit too extreme. Jona had an absolutely fantastic bracket in R1 and R2, and barely missed anything in the rounds that followed. This wasn't a case of someone blowing it later on, or of someone nailing the endgame but missing badly in the beginning. Jona was freaking consistent. If we reduce that R4 match's value by just 2 points, Jona wins.
Another issue with the extreme scaling is that it completely knocks people out of even looking reputable if they miss a late match. Going into the second semi, I was tied with yoblazer and LMS, and a point behind Mr Lasastryke. They all finished off the leaderboard entirely, despite a nearly 30 point spread from 1st to 50th, just for missing one match.
So is there a problem? Yes, I think so.
I don't agree with the fix ZTPL proposed, though. Point values should not be, strictly speaking, based on difficulty. Selecting an R4 match should inherently be more difficult than an average R1 match. Sure, there are some 8-9's that might be close in R1, but there's also 2-15 blowouts that are completely trivial. It's also natural that picking the correct champion in the contest is more significant than picking a match at the beginning of the contest. So I do believe incremental scaling is necessary, and I do believe that it ought to be geometric rather than arithmetic. I played with a 1-2-3-4-5-6-7 scale, and while it gets the job done, it doesn't feel satisfying.
If a game scales too slowly (or not at all,) then someone who gets ahead can clinch victory well before the end and have it be anticlimactic. This happens frequently in Jeopardy, even with the possibility to double up at the end. It's also the case in most sports, where the team that's ahead just runs out the clock. However, if a game scales too quickly, as I've often seen in many game shows and home-made trivia contests (like in school,) the ending carries so much weight as to render the rest of the proceedings irrelevant. An extreme case of this is Quidditch, where the golden snitch is worth 150 points, and no team ever scores more than 15 goals in the meanwhile to outweigh the capture of the snitch. Yes, Rowling wrote an exception, just to have there be one, but let's not derail here, please.
My hypothesis is that each round should be worth more than the round before, but not twice as much.
As such, the scale factor that I propose is r=1.71 -- which is to say, the cube root of 5. An odd choice, perhaps, but let's look at how the numbers look.
R1 - 1
R2 - 2 (1.7)
R3 - 3 (2.9)
R4 - 5
R5 - 8 (8.5)
R6 - 15 (14.6)
R7 - 25
This is very close to Fibonacci scaling, but the numbers are a little more pleasant than 13 and 21. Under this system, Jona would have won the bracket with me in second, the folks who bombed in the semi would be punished far less, but the contest still has a feeling of ramping up toward an exciting conclusion where the ending does indeed matter.
There is a beautiful elegance to the doubling per round, and so I understand its defense. It also has historical precedent with March Madness and the like. However, if we're truly being interested in "fairness" while maintaining contest excitement levels to the end, I feel like this is the optimal balance.